Meta Llama 2, once released captured the attention of the entire world. Starwhale has specially developed the Llama 2-Chat and Llama 2-7b model packages. In just 5 minutes, you can engage in a conversation with Llama 2-Chat from scratch on https://cloud.starwhale.cn.
In the future, we will also provide model packages for Llama 2-13b and Llama 2-70b. Interested friends, please stay tuned!
The following will provide a detailed introduction to what is Llama 2, what is Starwhale, and how to use Starwhale to run Llama 2-Chat.
What is Llama 2
The Llama 2 series models are a set of large language models that utilize optimized autoregressive Transformer architecture. They have undergone pre-training and fine-tuning and come in three parameter versions: 7 billion, 13 billion, and 70 billion. Additionally, Meta has trained a 34 billion parameter version, but it has not been released, and relevant data is mentioned in the research paper.
Pre-training: Compared to Llama 1, Llama 2's training data has increased by 40%, using 2 trillion tokens for training, and the context length is twice that of Llama 1, reaching 4096. Llama 2 is well-suited for various natural language generation tasks.

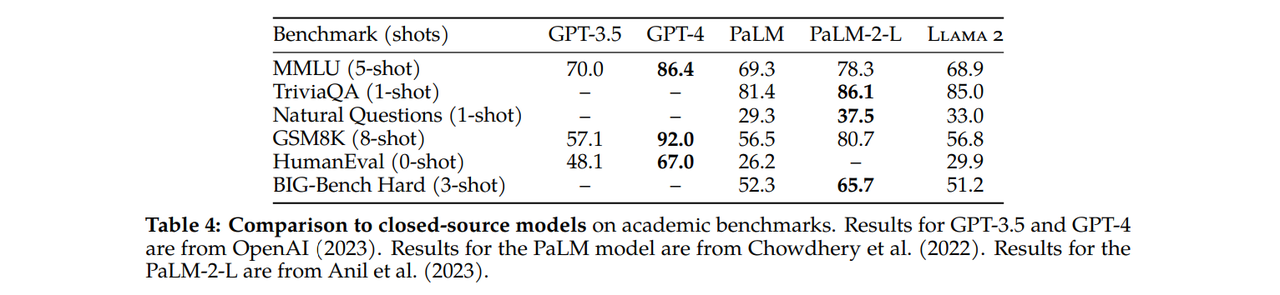
Meta compared the results of Llama 2-70b with closed-source models and found that its performance is close to GPT-3.5 on MMLU (Multilingual Multimodal Language Understanding) and GSM8K (German Speech Recognition) tasks. However, there are significant differences in performance on encoding benchmarks.
Moreover, on almost all benchmarks, Llama 2-70b performs on par with or even better than Google's PaLM-540b model. But there still remains a considerable gap in performance when compared to models like GPT-4 and PaLM-2-L.
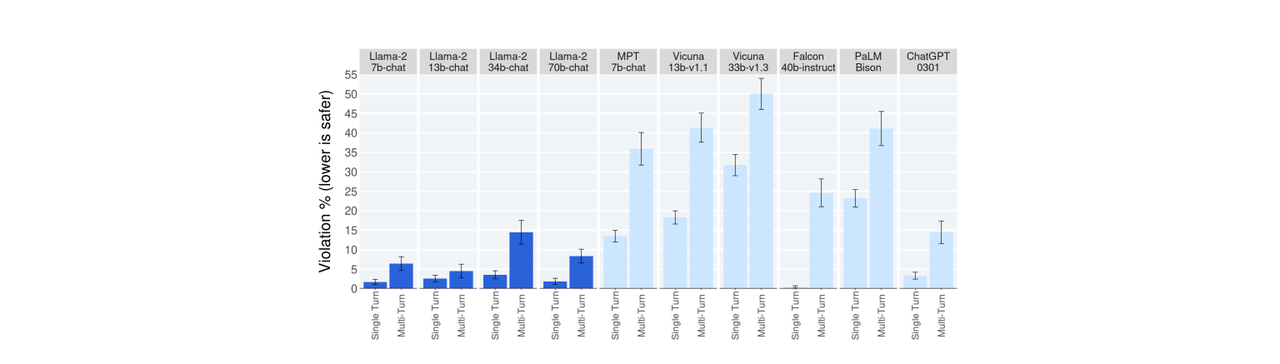
Fine-tuning: Llama 2-Chat is a version of Llama 2 that has been fine-tuned specifically for chat dialogue scenarios. The fine-tuning process involves using SFT (Supervised Fine-Tuning) and RLHF (Reinforcement Learning from Human Feedback) in an iterative optimization to align better with human preferences and improve safety. The fine-tuning data includes publicly available instruction datasets and over one million newly annotated samples. Llama 2-Chat can be used for chat applications similar to virtual assistants. The image below shows the percentage of violations in single-turn and multi-turn conversations. Compared to the baseline, Llama 2-Chat performs particularly well in multi-turn conversations.
What is Starwhale
Starwhale is an MLOps platform that offers a comprehensive solution for the entire machine learning operations process. It enables developers and businesses to efficiently and conveniently manage model hosting, execution, evaluation, deployment, and dataset management. Users can choose from three different versions: Standalone, Server, or Cloud, based on their specific requirements. For more detailed information and instructions on using Starwhale, users can refer to the platform's documentation.
how to use Starwhale to run Llama 2-Chat
Workflow:Login → Create a project → Run the model → Chat with Llama2
1. Login
First, you need to log in to the Starwhale platform by clicking on the login. If you haven't registered yet, you can click on the sign-up to create an account.
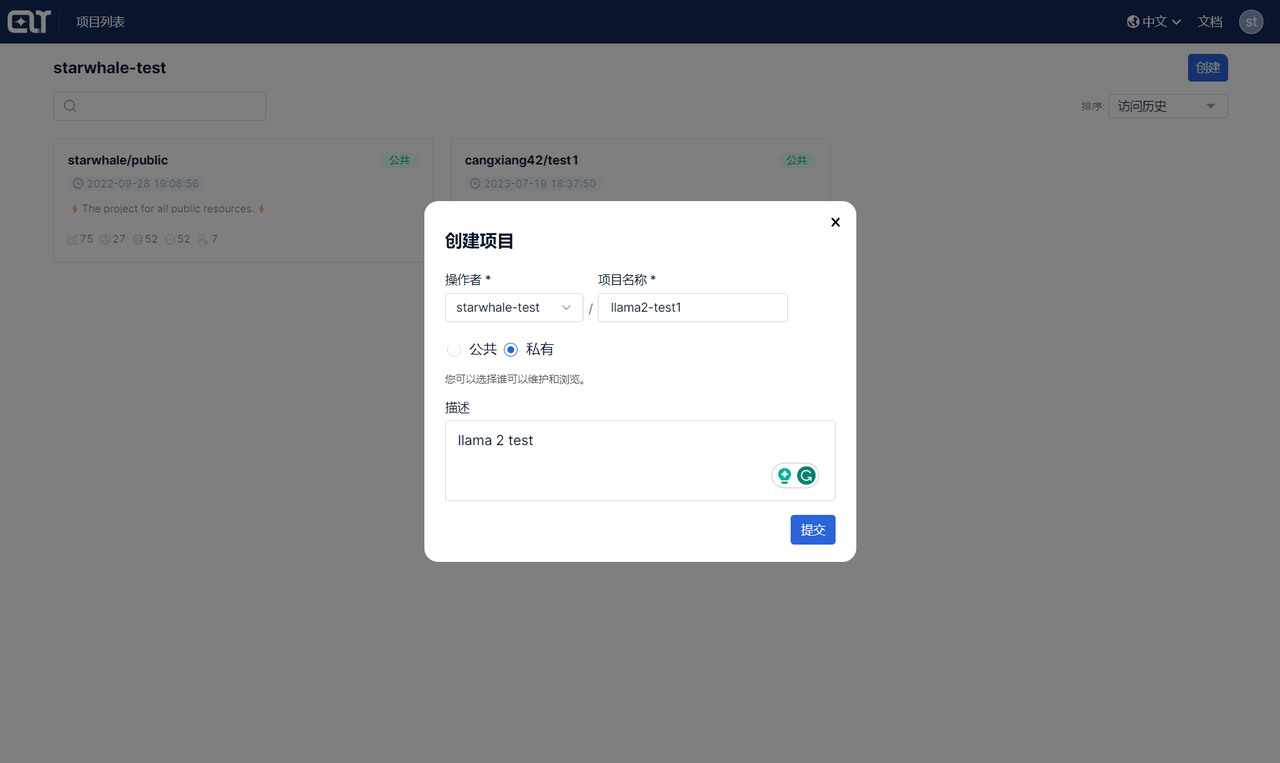
2. Create a project
After successful login, you will be directed to the project list page. Click on the Create button on the top right corner to create a new project. Enter the project name and click on the Submit button to create the project.
3. Run the model
Go to the job list page and click on the Create task button.
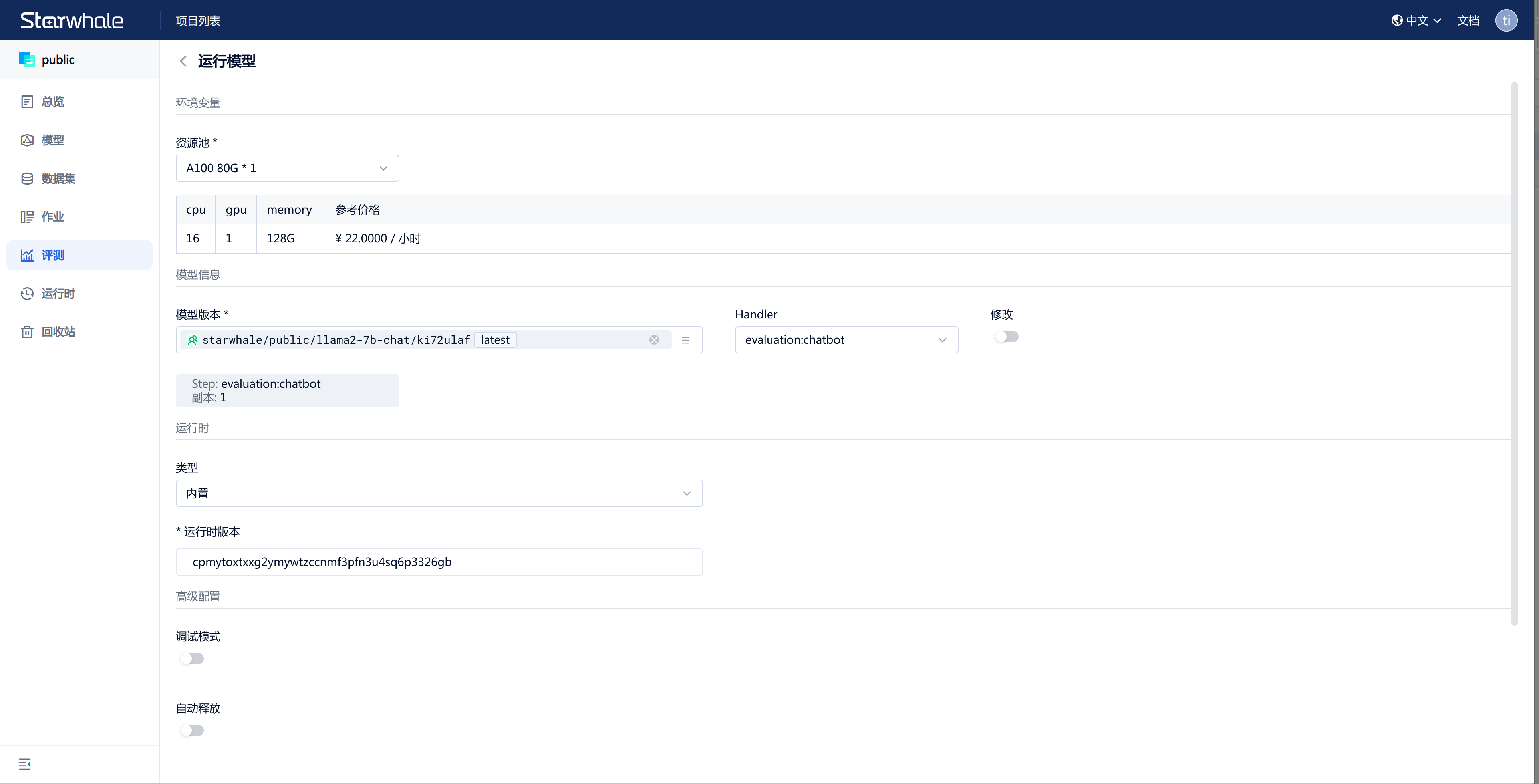
1) Choose the running resource, you can select A100 80G1 (recommended) or A10 24G1. 2) Select the model: starwhale/public/llama2-7b-chat/ki72ulaf(latest). 3) Choose the handler: Run the chatbot model, select the default option: evaluation:chatbot. 4) Choose the runtime: Select the default option, built-in. 5) Advanced configuration: Turn on the auto-release switch, where you can set the duration after which the task will be automatically canceled. If you don't set auto-release, you can manually cancel the task after the experiment is completed.
Click on Submit to run the model.
4. View the Results and Logs
The job list page allows you to view all the tasks in the project.
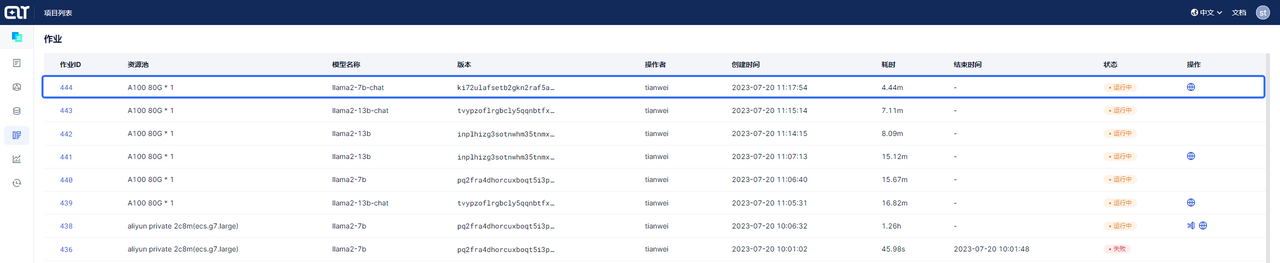
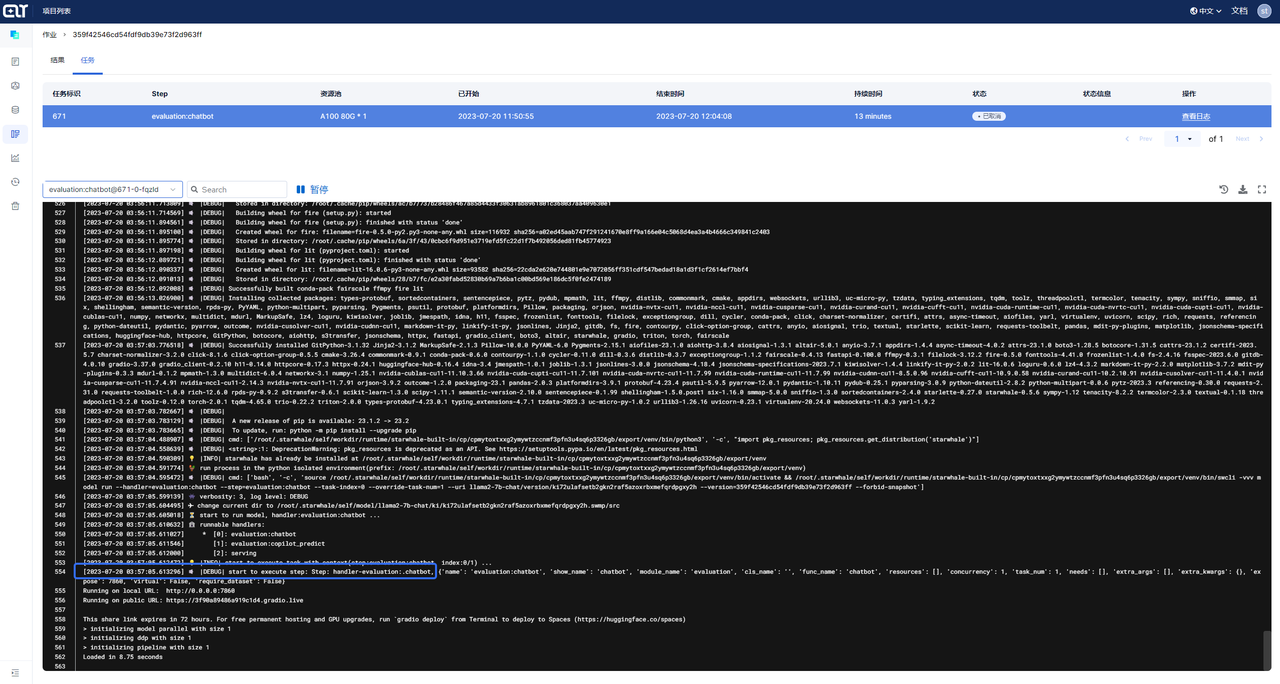
Click on the Job ID to enter the task details page, and then click on View Logs to see the logs.
The total time taken from task submission to model execution is 5 minutes.
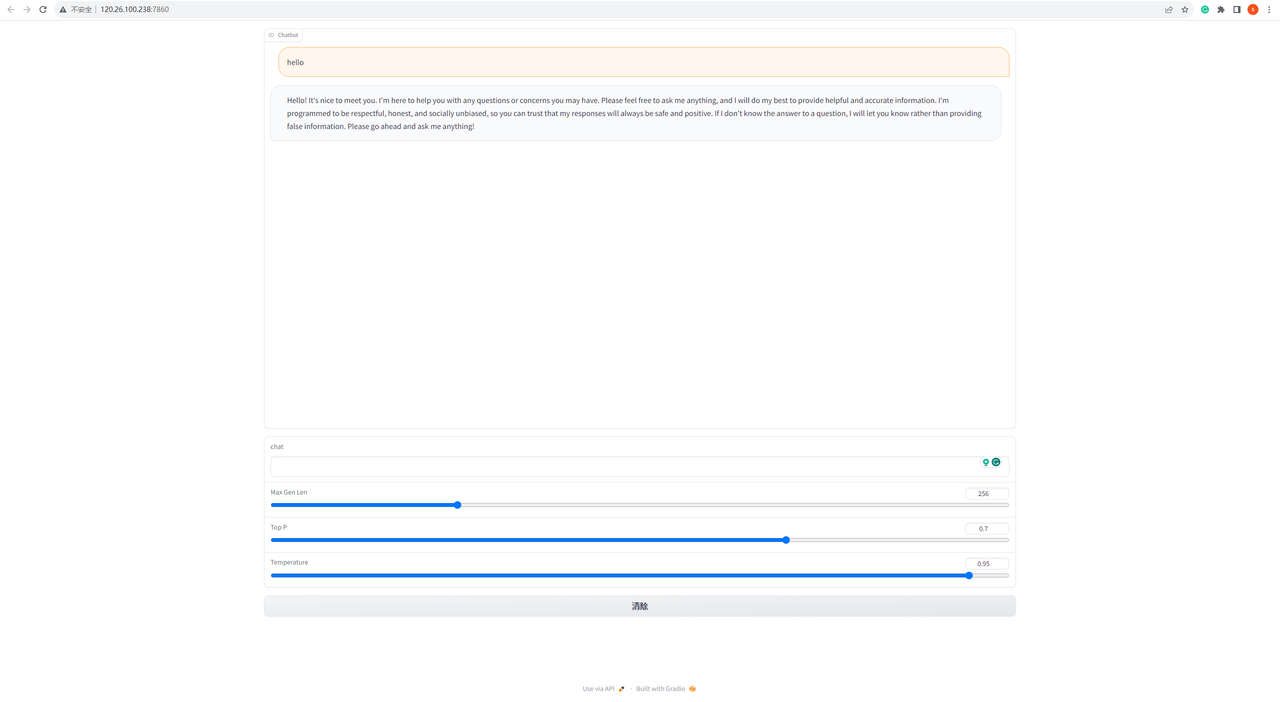
Once the execution is successful, return to the task list and click on the Terminal button to open the chatbox page. You can now start a conversation with Llama 2-Chat on the chatbox page.
These are the instructions on how to use Starwhale Cloud to run Llama 2-Chat. If you encounter any issues during the process, please feel free to leave a private message. You can also visit the Starwhale official website for more information. Thank you for your attention and support.